Software
Foma
Foma is a compiler, programming language, and C library for constructing finite-state automata and transducers for various uses. It has specific support for many natural language processing applications such as producing
morphological analyzers. Although NLP applications are probably the main use of foma, it is sufficiently generic to use for a large number of purposes. The foma interface is compatible with the Xerox xfst interface, and also contains a number of extensions for grammar compilation. The library contains efficient implementations of all classical automata/transducer algorithms: determinization, minimization, epsilon-removal, composition, boolean operations. Also, more advanced construction methods are available: context restriction, quotients, first-order regular logic, transducers from replacement rules, etc.
Treba
Treba is a basic command-line tool for training, decoding, and calculating with Hidden Markov Models (HMMs) and weighted (probabilistic) finite state automata (PFSA). It trains PFSA/HMMs, decodes, calculates sequence probabilities and generates sequences of PFSA. It includes a parallel implementation of HMM/PFSA training with Baum-Welch (optionally with deterministic annealing) for multiple CPUs/cores and a Gibbs sampler for estimating probabilities of PFSA/HMMs. Also supports inference of deterministic PFSA using state-merging algorithms with various knobs to tweak (ALERGIA/MDI).
Geoloc KDE

Text-based geolocation classifier. Used for geolocating tweets based on text features in
this paper. Comes with a visualization tool.
Pextract
A morphology learning tool that, given inflection tables as input, generalizes the tables into abstract paradigms. It does so by extracting the longest common subsequence (LCS) from each table, and labels the pieces of the LCS as variables. If any tables are identical after the LCS is extracted, they are collapsed into the same paradigm. Information about what the variables were assumed to contain is stored. For details, see
this paper, and for an application, see
this and
this.
PyPerceptron
Simple speed-optimized multi-class averaged perceptron library for Python. Written in C.
2nfa
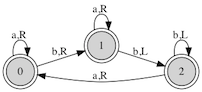
Convert 2-way automata (2NFA/2DFA) into the equivalent 1-way automata. The paper that describes the algorithm is available
here.
Palindrome generator

Palindrome generator written in Perl that takes advantage of language models to generate random palindromic sentences in the language of your choice. Plug in your model and one-up
Peter Norvig! Category: silly-but-may-contain-a-germ-of-insight.
Online Young and Morgan

A searchable interface to the monumental "Young & Morgan", i.e.
The Navajo Language: A Grammar and Colloquial Dictionary, by Robert W. Young and William Morgan; also known as YM87. Allows complex regular expression queries and contains some 15,000 entries in the Navajo section, and over 8,000 in the English-Navajo section. Apart from dictionary and grammatical information, the translated examples and definitions in YM87 provide a searchable 700,000 word corpus of the language.